The Data Journalism discipline is all about telling interesting and important stories with a data focused approach. Data Journalism has come about naturally with more information becoming available as data. A story may be about the data or informed by data.Data journalism is a type of journalism reflecting the increased role that numerical data is used in the production and distribution of information in the digital era. It reflects the increased interaction between content producers (journalist) and several other fields such as design, computer science and statistics. The post Data Science Glossary: What is Data Journalism appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/35hLTz8
0 Comments
A greedy algorithm will break a problem down into a series of steps. It will then look for the best possible solution at each step, aiming to find the best overall solution available.Greedy is an algorithmic paradigm that builds up a solution piece by piece, always choosing the next piece that offers the most obvious and immediate benefit. So the problems where choosing locally optimal also leads to global solution are best fit for Greedy. For example consider the Fractional Knapsack Problem. The local optimal strategy is to choose the item that has maximum value vs weight ratio. This strategy also leads to global optimal solution because we allowed to take fractions of an item. The post Data Science Glossary: What are Greedy Algorithms? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/2IjVYCk Algorithms that use fuzzy logic to decrease the runtime of a script. Fuzzy algorithms tend to be less precise than those that use Boolean logic. They also tend to be faster, and computational speed sometimes outweighs the loss in precision.In fuzzy mathematics, fuzzy logic is a form of many-valued logic in which the truth values of variables may be any real number between 0 and 1 both inclusive. It is employed to handle the concept of partial truth, where the truth value may range between completely true and completely false. The concept of fuzzy logic had been studied since the 1920’s. The term fuzzy logic was first used with 1965 by Lotfi Zadeh a professor of UC Berkeley in California. He observed that conventional computer logic was not capable of manipulating data representing subjective or unclear human ideas. Fuzzy logic has been applied to various fields, from control theory to AI. It was designed to allow the computer to determine the distinctions among data which is neither true nor false. Something similar to the process of human reasoning. The post Data Science Glossary: What are Fuzzy Algorithms appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/3eBfW7I A data warehouse is a system used to do quick analysis of business trends using data from many sources. Data Warehouses are designed to make it easy for people to answer important statistical questions without a Ph.D. in database architecture.In computing, a data warehouse, also known as an enterprise data warehouse, is a system used for reporting and data analysis, and is considered a core component of business intelligence. DWs are central repositories of integrated data from one or more disparate sources. A data warehouse architecture is made up of tiers. The top tier is the front-end client that presents results through reporting, analysis, and data mining tools. The middle tier consists of the analytics engine that is used to access and analyze the data. The bottom tier of the architecture is the database server, where data is loaded and stored. Data is stored in two different types of ways: 1) data that is accessed frequently is stored in very fast storage (like SSD drives) and 2) data that is infrequently accessed is stored in a cheap object store, like Amazon S3. The data warehouse will automatically make sure that frequently accessed data is moved into the “fast” storage so query speed is optimized. Benefits of a data warehouse include the following:
The post Data Science Glossary: What is a Data Warehouse? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/3p34QgF An algorithm is a set of instructions we give a computer so it can take values and manipulate them into a usable form.In mathematics and computer science, an algorithm is a finite sequence of well-defined, computer-implementable instructions, typically to solve a class of problems or to perform a computation. Algorithms need to have their steps in the right order. Think about an algorithm for getting dressed in the morning. What if you put on your coat before your jumper? Your jumper would be on top of your coat and that would be silly! When you write an algorithm the order of the instructions is very important. This can be as easy as finding and removing every comma in a paragraph, or as complex as building an equation that predicts how many home runs a baseball player will hit in 2020. The post Data Science Glossary: What is an Algorithm appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/350GdcD 
In our previous tutorial, we became familiar with the ARMA model. Let’s get started, shall we? What is an ARIMA model?As usual, we’ll start with the notation. An ARIMA model has three orders – p, d, and q (ARIMA(p,d,q)). The “p” and “q” represent the autoregressive (AR) and moving average (MA) lags just like with the ARMA models. The “d” order is the integration order. It represents the number of times we need to integrate the time series to ensure stationarity, but more on that in just a bit. How is ARIMA related to ARMA?Any model of the sort ARIMA (p, 0, q) is equivalent to an ARMA (p, q) model since we are not including any degree of changes. Of course, an ARIMA (0, 0, q) and an ARIMA (p, 0, 0) would also be the same as an MA(q) and an AR(p) respectively. How do ARIMA models work?These integrated models account for the non-seasonal difference between periods to establish stationarity. What does a simple ARIMA (1,1,1) look like?Okay, since now we know this, let’s have a look at the equation of a simple ARIMA model, with all orders equal to 1. Suppose P is the price variable we’re trying to model. Then, the simple ARIMA equation for P would look as follows: ΔPt =c+ϕ1 ΔPt-1 + θ1 ϵt-1 +ϵt Just like we did in the other tutorials on time series models, let’s go over all the moving parts of this equation and break it down, so we can understand it better. For starters, Pt and Pt-1 represent the values in the current period and 1 period ago respectively. Similarly, ϵ t and ϵ t-1 are the error terms for the same two periods. And, of course, c is just a baseline constant factor. The two parameters, ϕ 1 and θ1, express what parts of the value (Pt-1) and error (ϵ t-1) last period are relevant in estimating the current one. Here’s an easy way to think about ARIMA models.Essentially, the entire ARIMA model is nothing more than an ARMA model for a newly generated time-series, which is stationary. How do we determine the orders of an ARIMA model?We saw that the ARMA doesn’t have any functions like the ACF or PACF which suggest what the optimal order for the different components is. We can say the same about the ARIMA. After all, it’s a more complex model based on ARMA. So, our best bet is to start simple, check if integrating once grants stationarity. If so, we can fit a simple ARIMA model and examine the ACF of the residual values to get a better feel about what orders to use. Peculiarities of integrated modelsIt’s important to note that we lose d-many observations when we deal with integrated values. This comes from the fact that there is no “previous” period, where we wish to integrate the very first day of the dataset. Simply put, we can’t find the difference between the first element and the one preceding it, because it doesn’t exist. Similarly, if we integrate two times, we lose two observations, one for each integration. Even though we’d have an integrated difference in prices for the second day of the dataset (ΔP2 = P 1 – P2), wouldn’t have one for the first (ΔP 1= P0– P1), to compare it with. Therefore, we’d also have a missing value for the second day of the time-series, after integrating twice (Δ2P2= ΔP1– ΔP2). If you want to learn more about implementing ARIMA models in Python, or how the model selection process works, make sure to check out our step-by-step Python tutorials. Ready to take the next step towards a career in data science?Check out the complete Data Science Program today. Start with the fundamentals with our Statistics, Maths, and Excel courses. Build up a step-by-step experience with SQL, Python, R, Power BI, and Tableau. And upgrade your skillset with Machine Learning, Deep Learning, Credit Risk Modeling, Time Series Analysis, and Customer Analytics in Python. Still not sure you want to turn your interest in data science into a career? You can explore the curriculum or sign up for 15 hours of beginner to advanced video content for free by clicking on the button below. The post What Is an ARIMA Model? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/34Q6CbS 
Data warehousing is one of the hottest topics both in business and in data science. But if you’re new to the field, you’re probably wondering what a data warehouse is, why we need it, and how it works. Don’t worry because, in this article, you’ll find the answers to all these questions. First, let’s start with a definition: the meaning of the phrase: ‘Single source of truth’. What Is the Single Source of Truth?In information systems theory, the ‘single source of truth’ is the practice of structuring all the best quality data in one place. Here’s a very simple example. Surely it has happened to you to work on a file and to create many different versions of it. How do you name such a file?Well, once you are ready you often place the word ‘final’ at the end. This results in having a bunch of files with extensions:
Or my favorite:
If this is you, you are not alone. It seems that even corporations never know where the most recent or most appropriate file is. 
But what if you knew that there is one single place where you would always have the single source of information?That would be quite helpful wouldn’t it? Well, a data warehouse exists to fill that need. So, what is a data warehouse exactly?
It is the place where companies store their valuable data assets, including customer data, sales data, employee data, and so on. In short, a data warehouse is the de facto ‘single source of data truth’ for an organization. It is usually created and used primarily for data reporting and analysis purposes. There are several defining features of a data warehouse.It is:
Let’s quickly go through these, one by one. Subject-oriented means that the information in a data warehouse revolves around some subject.Therefore, it does not contain all company data ever, but only the subject matters of interest. For instance, data on your competitors need not appear in a data warehouse, however, your own sales data will most certainly be there. 
Integrated corresponds to the example from the beginning of the video.Each database, or each team, or even each person has their own preferences when it comes to naming conventions. That is why common standards are developed to make sure that the data warehouse picks the best quality data from everywhere. This relates to ‘master data governance’, but that is a topic for another time. 
Time-variant relates to the fact that a data warehouse contains historical data, too.As said before, we mainly use a data warehouse for analysis and reporting, which implies we need to know what happened 5 or 10 years ago. 
Nonvolatile implies that the data only flows in the data warehouse as is.Once there, it cannot be changed or deleted. 
Summarized once again touches upon the fact that the data is used for data analytics.Often it is aggregated or segmented in some ways, in order to facilitate analysis and reporting. 
So, that’s what a data warehouse is – a very well structured and nonvolatile, ‘de facto’, single source of truth for a company. Ready to take the next step towards a data science career?Check out the complete Data Science Program today. Start with the fundamentals with our Statistics, Maths, and Excel courses. Build up a step-by-step experience with SQL, Python, R, Power BI, and Tableau. And upgrade your skillset with Machine Learning, Deep Learning, Credit Risk Modeling, Time Series Analysis, and Customer Analytics in Python. Still not sure you want to turn your interest in data science into a career? The post What Is a Data Warehouse? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/34NPC5W 
Starting off as a data analyst intern is one of the best ways to begin a career in the field of analytics and data science if you don’t have any prior working experience. The benefits of a data analyst internship are countless, beginning with the opportunity to be mentored by professionals in the field and build up your analytics skillset, up to exploring the numerous networking opportunities that internships provide. So, in this article, we’ll discuss how to become a data analyst intern. We’ll look at who the data analyst intern is, what do they do, and what skills and education you need to become one. You can also check out our video on the topic below or scroll down to keep on reading. 
Who Is the Data Analyst Intern?Data analyst intern is an entry-level position that plays an auxiliary role in the analytics department of a company. That means a data analyst intern supports both data analysts and data scientists in their projects; usually by performing various data mining or data quality tasks. 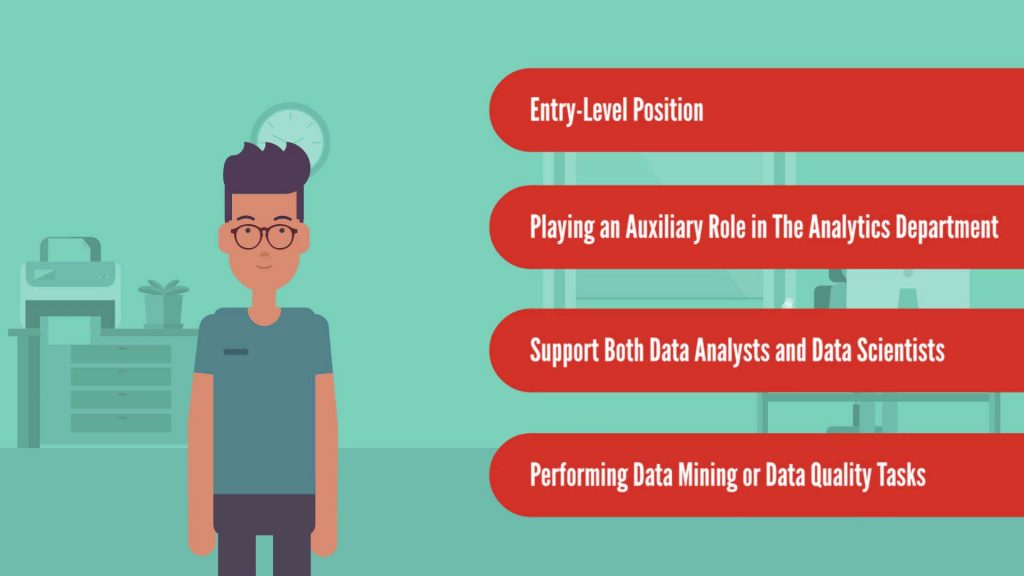
In other words, their ultimate goal is to take some run-of-the-mill operations off the hands of the more senior data analysts and data scientists. However, don’t be quick to judge this internship as a boring service job. it’s a quid-pro-quo game. In turn, full-time data analysts and data scientists have less workload. And that makes them happy to spend time showing data analyst interns key practical aspects of their work. That said, data analyst interns are usually assigned to a data analyst or a data scientist who provides them with advice and technical guidance throughout the internship. Yet sometimes, a data analyst intern is part of a team and has pre-defined duties. At least that’s the case in team structures where there’s always an intern on a rolling basis. What Does a Data Analyst Intern Do?A data analyst intern is hired in an organization to basically audition for the data analyst role. Most often they’re given tasks revolving around working with data and preprocessing it, monitoring data quality and consistency. Sometimes data analyst interns also work with data stewards to improve the quality, accessibility, and value of the company’s data. 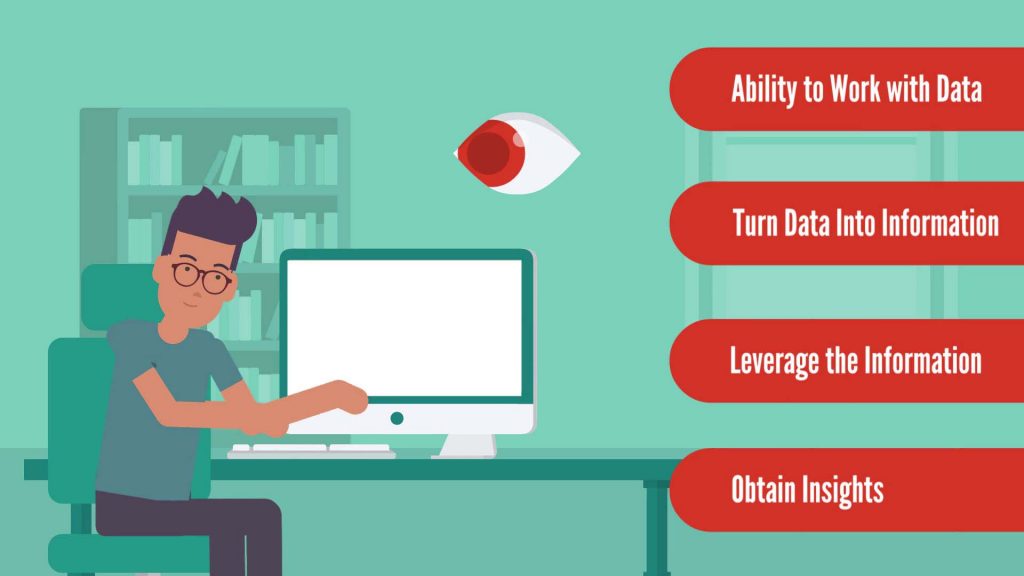
In the meantime, Big Brother is watching – throughout the internship, current data analysts monitor the ability of interns to work with data, turn it into information, then leverage the information and obtain insights that can be used to improve business decisions. A data analyst intern needs to show they are perfectly capable of deriving insights and communicating the results from their findings. Their goal during the internship should be to demonstrate that they are detailed-oriented professionals who can answer critical business questions by using available data sources. 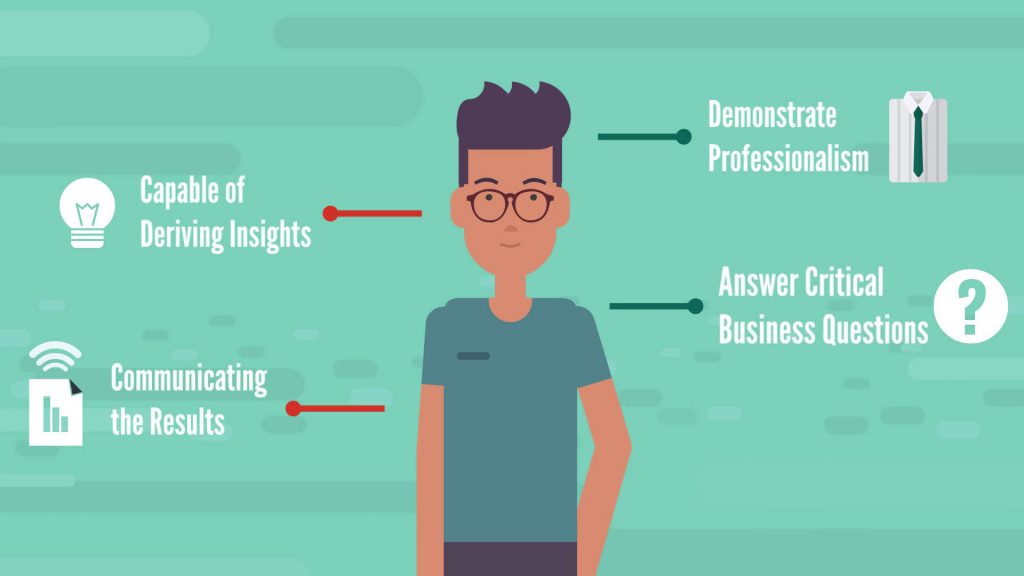
Sounds cool, doesn’t it? A data analyst career is a great option to explore, both on its own and as a gateway into a data scientist position. And a data analyst internship can be the first step on the data scientist career path. Many companies across literally all industries offer internship positions as part of their recruitment strategy, especially large firms who like to select their talent carefully and can dedicate the necessary management resources to an internship program. What Skills Do You Need to Apply for a Data Analyst Internship?We researched many job postings to discover the desired tools and skills data analyst intern candidates must have. For the record, 25% of the job ads belong to companies with 10,000 or more employees. So, here’s what the data says:

But don’t think that being tech-savvy is the only thing that matters. At least 50% of the job postings make an emphasis on communication. So, you need to work on your soft skills as well. After all, one of the key prerequisites is to be able to share your findings with people from the business. What Degree Do You Need to Become a Data Analyst Intern?50% of data analyst internships require a Bachelor’s degree… and the rest didn’t… That means formal education is not that important as long as you’re well-versed in statistics, preprocessing with programming languages, ability to work with data and navigate databases, ability to extract information from data and turn it into insights, and willingness to go the extra mile and engage with data mining and data quality tasks. 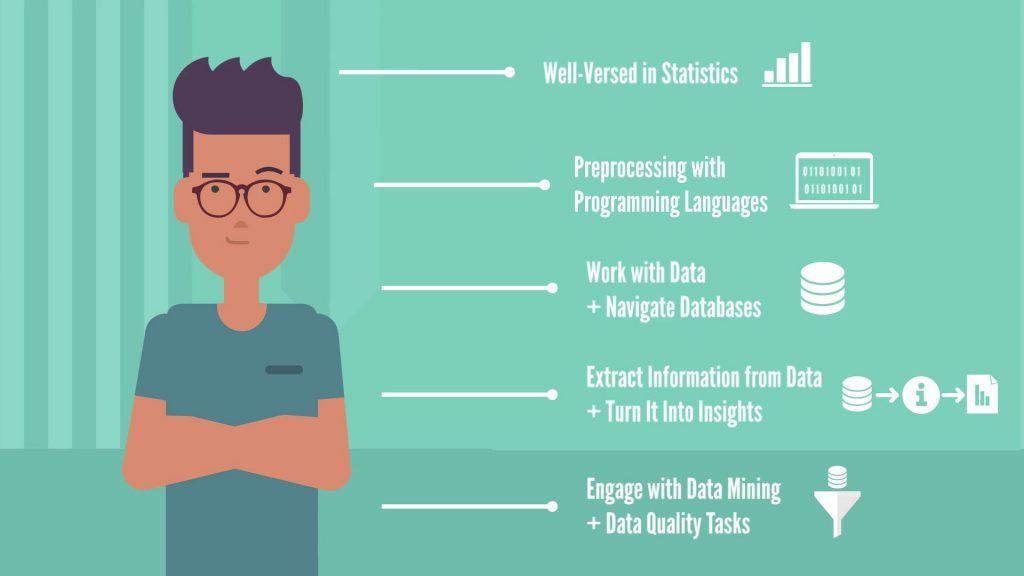
Next Steps: Starting a Data Analyst CareerOverall, to be successful in this position, you need:
Ideally, you should be able to see how these methods can be applied in practice in a business environment. In fact, it will benefit you greatly if you have already learned these skills prior to your internship. This way, you’ll make the best possible impression, which is super important because – as we mentioned earlier – this is your audition to a full-time data analyst role and a data scientist job. Now you’re aware of the most important aspects of the data analyst intern position. And you know what skills to focus on in order to become one. Nevertheless, if you feel like you still need additional career advice and a more detailed analysis of the career opportunities in data science, check out our course Starting a Career in Data Science: Project Portfolio, Resume, and Interview Process. The post How to Become a Data Analyst Intern? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/2GL9dvK 
We’ve been developing this project for a while, and finally, the time has come to launch our newest collaboration with an acknowledged expert in the field of AI and data science. We’re happy to announce the release of Product Management for AI & Data Science with Danielle Thé. Danielle Thé is a Senior Product Manager for Machine Learning with a Master’s in Science of Management. She boasts years of experience as a Product Manager and Product Marketing Manager in the tech industry for companies like Google and Deloitte Digital. In this course, she will teach you everything you need for a successful career as a Product Manager for AI and data science. You will learn the expert skills needed to manage the development of successful A.I. products: from defining the role of a product manager and making the difference between a product and a project manager, through executing business strategy for AI and data science, to sourcing data for your projects and understanding how this data needs to be managed. Danielle will take you through the full lifecycle of an AI or data science project in a company. What is more, she will illustrate how to manage data science and AI teams, improve communication between team members, and how to address ethics, privacy, and bias. This 12-part course gives you access to over 60 lessons, each paired with resources, notes or articles that complement the notions covered. You’ll also practice with quizzes, assignments and projects to put what you’ve learned into action. Product Management for AI & Data Science is part of the 365 Data Science Online Program, so existing subscribers can access the courses at no additional cost. To learn more about the course curriculum or subscribe to the Data Science Online Program, please visit our Courses page. Happy Learning! The post Product Management for AI & Data Science appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/3iUYJH1 Have you ever been in a situation where you spend a lot of your time and energy learning something, only to realize that the skills you have gained don’t match or live up to the requirements listed by the employer? If this happens to you, you’ll have to begin learning new technologies and skills to get to the interview, which is one of the most painful and tedious tasks in the job searching process. Unfortunately, many people go through this tiresome loop. With the recent buzz around machine learning, many courses have come into existence offering a broad curriculum. This leaves job seekers confused about what they really need to learn to become machine learning engineers. So, today we will try to find a solution and put you one step ahead of your rival ML job seekers. After our previous analysis of Data scientist job descriptions, we have received numerous requests from people asking about a similar analysis on machine learning. That is why we conducted this analysis in an identical manner – by leveraging job boards data. We analyzed more than 500 recent machine learning engineer job postings, and this analysis was mainly focused on the USA. Now, let’s set our expectations straight from the start. We will try to answer the most common questions every machine learning engineer enthusiast needs to know.
You can find the answers to all these questions in the video below or just scroll down to keep reading. 
Machine Learning Engineer DegreeWhat is the most sought-after educational background? Well, this is one of the most common questions among job seekers because there is a lot of confusion in the job market. Nobody has a clear idea about the ideal educational background required to become a machine learning engineer. So, let’s see what the data tells us. 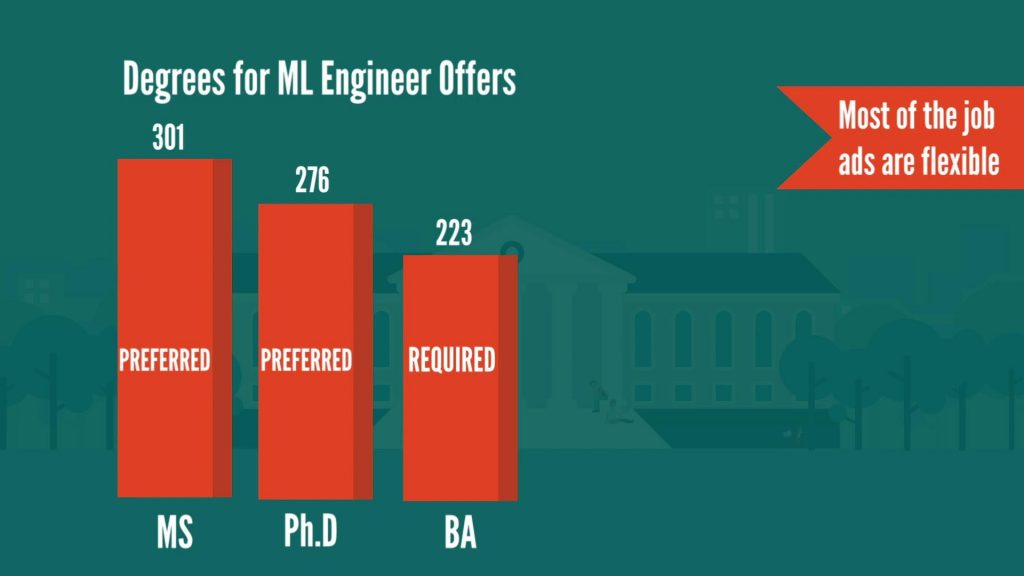
According to our research:
In addition, what is worth noting is that most of the job ads are flexible in terms of the type of degree. For example, very often we can see Bachelor’s as required and Master’s/Ph.D. as preferred. In terms of degree specialization, it appears that Computer Science, with Statistics and Mathematics as the not-so-close second and third place are the three specializations employers are looking for the most. Electrical engineering and physics are the other two most frequently desired degrees. 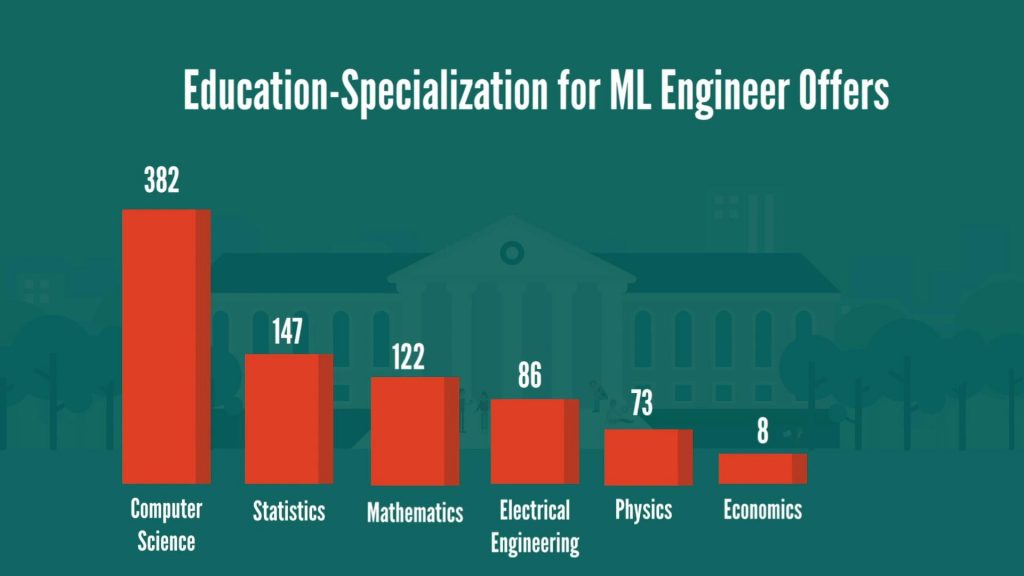
Now that we’ve covered the degrees and fields of study required to become a machine learning engineer, let’s take a look at the companies that are actively recruiting. Who are they? Top 10 Companies Offering Machine Learning Engineer JobsHere are the top 10 companies in our dataset with the most machine learning engineer job openings. 
As you can see, Apple undisputedly tops the list with almost 60 available offers, followed by Twitter, Amazon, Facebook, Snapchat, and TikTok. These are some of the most exciting firms in tech field, which extensively rely on machine learning to run their platforms. So, no surprise here. Regarding company size, it is obvious that the majority of the offers are coming from big firms with more than 10,000 employees. However, there is a considerable number of postings by both mid-range firms (1000 to 10,000 employees) and smaller firms (with less than 500 employees). 
Next in our study, we analyzed the industries with the highest concentration of machine learning engineer job offers. Machine Learning Engineer Jobs by IndustryUnsurprisingly, there are more postings in the IT and Retail/Wholesale industries at the moment. But these are far from your only options, as there’s a substantial number of offers in the Consulting, Education, and Finance industries, as well. 
This gives us an idea about the companies hiring ML engineers. However, to be thorough, we need to take a look at geography, too. Here, we split the data based on the state and city where the offers came from. Machine Learning Engineer Jobs by State and CityIn terms of states, the majority of machine learning offers (almost 50% of our data) are from the state of California. After California, there seem to be a good number of opportunities in New York, Washington, and Massachusetts. 
If we consider cities where these jobs were available, we can see three important findings:

Now that we’ve outlined the landscape for ML engineer job postings, it’s time to pay attention to one of the crucial factors to land this lucrative job – working experience. Machine Learning Engineer Work ExperienceAccording to the data, there are generally more offers for people with at least 2 years of relevant experience. For comparison, there seem to be more offers in the range of 1–5 years of experience and fewer opportunities for 5+ years-of-experience candidates and freshers at the moment. And that’s certainly good news for those of you who considered many years on the job as a hard prerequisite for this position. But let’s elaborate on the experience factor a bit more – this time in relation to degrees. 
On average, the experience required with a Bachelor’s degree is 4 years, while for Master’s degree, it’s roughly one year less – 3 years. 
On the other hand, if you hold a Ph.D., then you’ll need 2 years of experience. However, there is a little catch here, as most of the recruiters haven’t mentioned the required experience for Ph.D. holders specifically. They mentioned it in a generalized way like: Required 2+ years of experience with education in MS or Ph.D. So, overall, if you have a Bachelor’s degree, you stand a pretty good chance with ML employers, provided that you have worked for a few years and you have acquired some valuable experience. Moving forward, it’s time to dissect the most practical aspect of landing a machine learning engineer job – the required skillset. Machine Learning Engineer SkillsIn terms of general skills for the machine learning engineer position, we discovered the following: 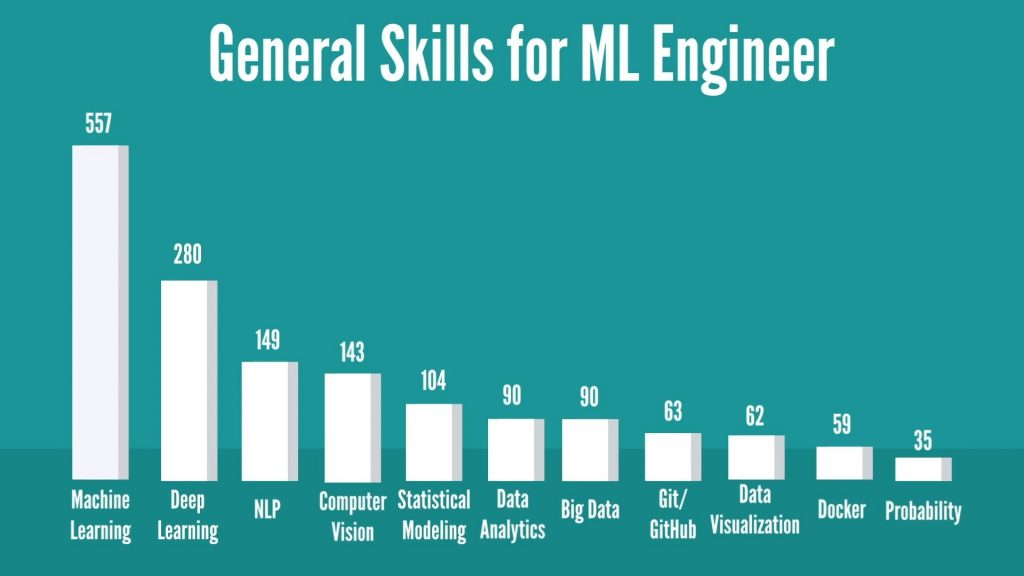
To be a machine learning engineer, obviously, machine learning is the primary skill required. In addition, most of the jobs have mentioned deep learning and its fields like Natural Language Processing (NLP) and computer vision as a requirement. But that’s not all! There have been plenty of mentions of data analytics, statistical modeling and data visualization, as well. Big Data, version control tools like Git and deployment tools like Docker have been requested in quite a few descriptions, too. How about we dive deep into each type of skills required? Starting with programming languages. Programming LanguagesNo surprise here – Python is leading the chart with a significant number. What’s worth noting is that C++ and Java are mentioned more frequently than R, and SQL is mentioned in quite a few jobs, as well. 
Deep Learning FrameworksContinuing with the most sought-after skills, we can’t skip deep learning frameworks: 
Tensorflow is leading our chart with Pytorch as a close second. Then the top two are followed by Caffe and Keras. Tensorflow and Pytorch definitely look like the two most popular frameworks at the moment. Machine Learning LibrariesBeing able to work with different packages that are suitable for the task at hand is an essential skill for a machine learning engineer. So, let’s examine the most frequently requested Python machine learning packages. 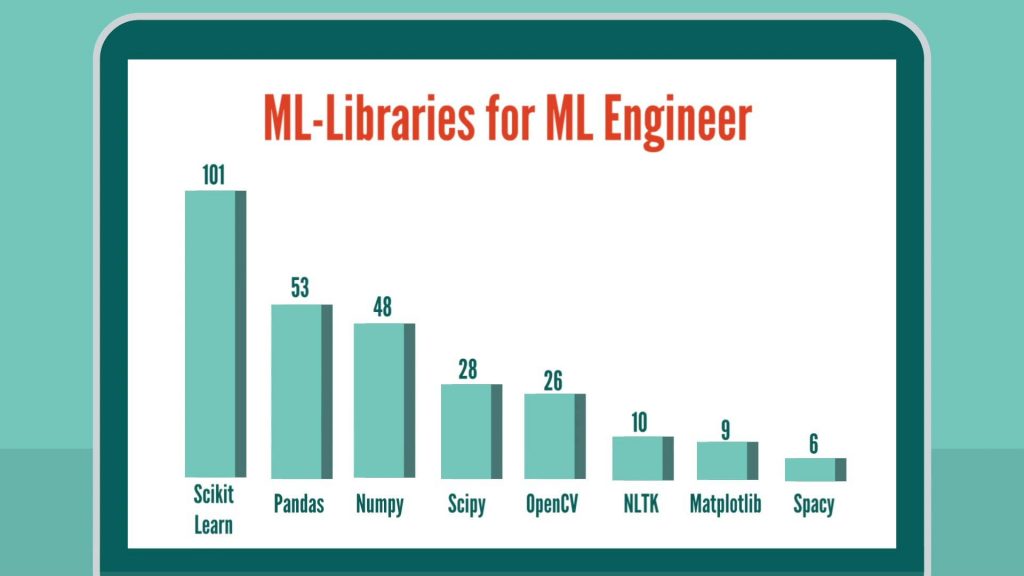
Scikit-learn, where most of the machine learning algorithms and all other important functions are available, is listed as the top package, followed by pandas – one of the important libraries for all data manipulation activities. In third place, we have NumPy and SciPy where, basically, all the important math functions reside. Big Data TechnologiesSpark tops the list with a significant lead over Hadoop, while Hive and Kafka have been mentioned in fewer job postings. 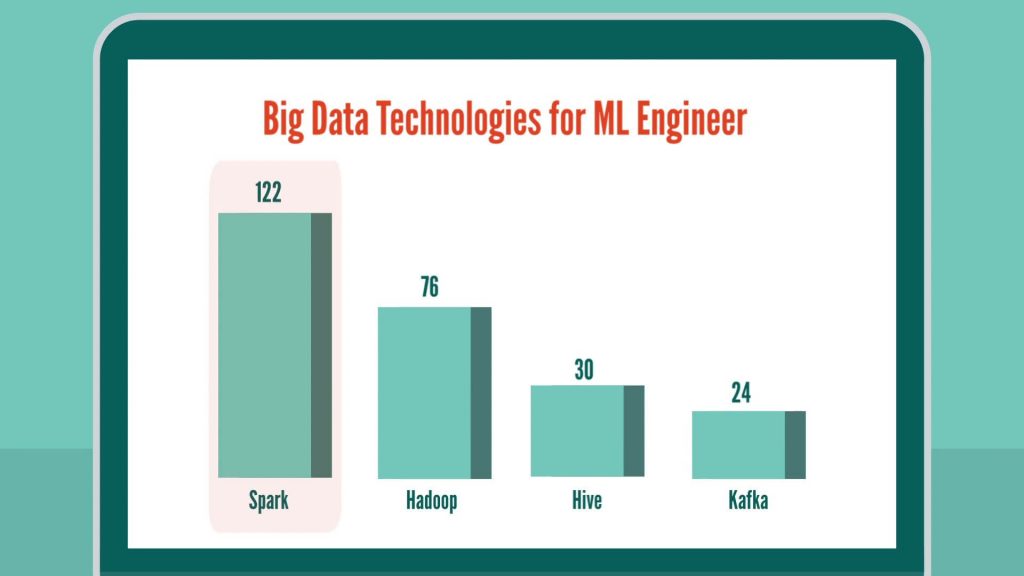
Cloud TechnologiesIn terms of cloud technologies, AWS is the most in-demand cloud technology at the moment with Google’s GCP and Microsoft’s Azure following in its footprints. 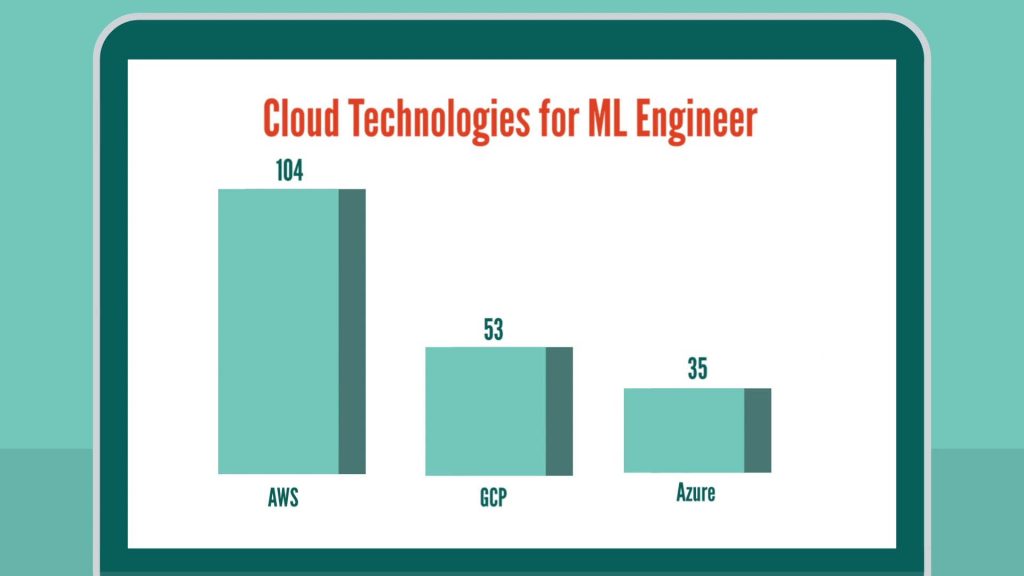
Data VisualizationAre data visualization skills important for an ML Engineer? 
According to the data – not really. In fact, there are very few mentions of Data visualization tools for machine learning jobs. Tableau was mentioned just 15 times, whereas Power BI only 2 times, which makes it clear that the default packages in Python should suffice for aspiring ML engineers when it comes to data visualization. Communication SkillsLast on the list of ML Engineer job requirements come communication skills. 
This one is slightly different than all the other skills we have seen until now. Apart from regular technical skills, communication skills appear to be equally important. Let’s see how many jobs have mentioned strong communication skills explicitly. 220 jobs have a mention of communication skills as a definite requirement for the desired candidate. How to Become a Machine Learning Engineer: Next StepsNow, you’ve got a good idea about the skills and education required to land a machine learning engineer job. One last piece of advice from our side: knowing technology is one thing and applying it is a whole different thing. So, to be successful in the ML field, learn the most mentioned important skills first. Then try to solve a real-world problem by combining all your skills to get a more real-life-like experience. Remember machine learning is a very dynamic field, so be ready to upgrade yourself every day. That said, if you want to sharpen your predictive modeling skills, check out our Machine Learning in Python course. The post How to Become a Machine Learning Engineer? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/3jMYjng |

 RSS Feed
RSS Feed
