|
A fairness metric that is satisfied if the results of a model’s classification are not dependent on a given sensitive attribute. For example, if both Lilliputians and Brobdingnagians apply to Glubbdubdrib University, demographic parity is achieved if the percentage of Lilliputians admitted is the same as the percentage of Brobdingnagians admitted, irrespective of whether one group is on average more qualified than the other. Contrast with equalized odds and equality of opportunity, which permit classification results in aggregate to depend on sensitive attributes, but do not permit classification results for certain specified ground-truth labels to depend on sensitive attributes. See “Attacking discrimination with smarter machine learning” for a visualization exploring the tradeoffs when optimizing for demographic parity. The post What is demographic parity in Machine Learning appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/3mX9bQg
0 Comments
In mathematics, casually speaking, a mixture of two functions. In machine learning, a convolution mixes the convolutional filter and the input matrix in order to train weights. The term “convolution” in machine learning is often a shorthand way of referring to either convolutional operation or convolutional layer. Without convolutions, a machine learning algorithm would have to learn a separate weight for every cell in a large tensor. For example, a machine learning algorithm training on 2K x 2K images would be forced to find 4M separate weights. Thanks to convolutions, a machine learning algorithm only has to find weights for every cell in the convolutional filter, dramatically reducing the memory needed to train the model. When the convolutional filter is applied, it is simply replicated across cells such that each is multiplied by the filter. The post What is convolution in Machine Learning appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/2KLWIlq A function in which the region above the graph of the function is a convex set. The prototypical convex function is shaped something like the letter U. For example, the following are all convex functions: 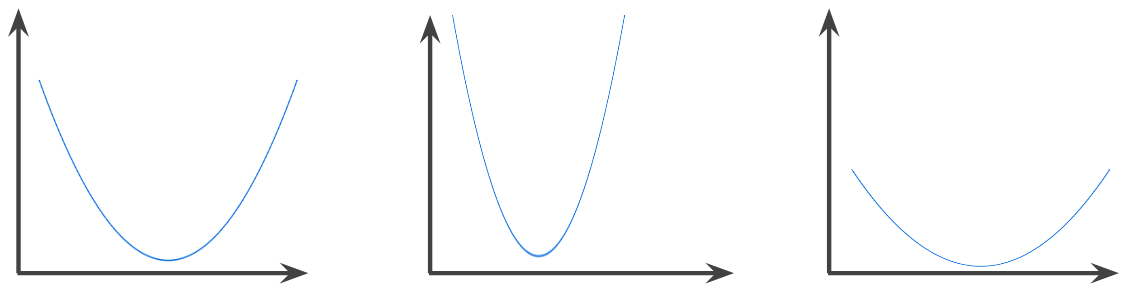
By contrast, the following function is not convex. Notice how the region above the graph is not a convex set: 
A strictly convex function has exactly one local minimum point, which is also the global minimum point. The classic U-shaped functions are strictly convex functions. However, some convex functions (for example, straight lines) are not U-shaped. A lot of the common loss functions, including the following, are convex functions:
Many variations of gradient descent are guaranteed to find a point close to the minimum of a strictly convex function. Similarly, many variations of stochastic gradient descent have a high probability (though, not a guarantee) of finding a point close to the minimum of a strictly convex function. The sum of two convex functions (for example, L2 loss + L1 regularization) is a convex function. Deep models are never convex functions. Remarkably, algorithms designed for convex optimization tend to find reasonably good solutions on deep networks anyway, even though those solutions are not guaranteed to be a global minimum. The post What is convex function in Machine Learning appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/3rEYhCb An NxN table that summarizes how successful a classification model’s predictions were; that is, the correlation between the label and the model’s classification. One axis of a confusion matrix is the label that the model predicted, and the other axis is the actual label. N represents the number of classes. In a binary classification problem, N=2. For example, here is a sample confusion matrix for a binary classification problem:
The preceding confusion matrix shows that of the 19 samples that actually had tumors, the model correctly classified 18 as having tumors (18 true positives), and incorrectly classified 1 as not having a tumor (1 false negative). Similarly, of 458 samples that actually did not have tumors, 452 were correctly classified (452 true negatives) and 6 were incorrectly classified (6 false positives). The confusion matrix for a multi-class classification problem can help you determine mistake patterns. For example, a confusion matrix could reveal that a model trained to recognize handwritten digits tends to mistakenly predict 9 instead of 4, or 1 instead of 7. Confusion matrices contain sufficient information to calculate a variety of performance metrics, including precision and recall. The post What is confusion matrix in Machine Learning? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/38F3OQv Grouping related examples, particularly during unsupervised learning. Once all the examples are grouped, a human can optionally supply meaning to each cluster. Many clustering algorithms exist. For example, the k-means algorithm clusters examples based on their proximity to a centroid, as in the following diagram: 
A human researcher could then review the clusters and, for example, label cluster 1 as “dwarf trees” and cluster 2 as “full-size trees.” As another example, consider a clustering algorithm based on an example’s distance from a center point, illustrated as follows: 
The post What is clustering in Machine Learning? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/2WMYFjR A technique for handling outliers. Specifically, reducing feature values that are greater than a set maximum value down to that maximum value. Also, increasing feature values that are less than a specific minimum value up to that minimum value. For example, suppose that only a few feature values fall outside the range 40–60. In this case, you could do the following:
In addition to bringing input values within a designated range, clipping can also used to force gradient values within a designated range during training. The post What is clipping in Machine Learning? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/3nQfN4f Features having a discrete set of possible values. For example, consider a categorical feature named Sometimes, values in the discrete set are mutually exclusive, and only one value can be applied to a given example. For example, a Categorical features are sometimes called discrete features. Contrast with numerical data. The post What is categorical data in Machine Learning? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/37PZgI5 Expanding the shape of an operand in a matrix math operation to dimensions compatible for that operation. For instance, linear algebra requires that the two operands in a matrix addition operation must have the same dimensions. Consequently, you can’t add a matrix of shape (m, n) to a vector of length n. Broadcasting enables this operation by virtually expanding the vector of length n to a matrix of shape (m,n) by replicating the same values down each column. For example, given the following definitions, linear algebra prohibits A+B because A and B have different dimensions:
However, broadcasting enables the operation A+B by virtually expanding B to:
Thus, A+B is now a valid operation:
See the following description of broadcasting in NumPy for more details. The post What is broadcasting in Machine Learning? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/3rtLQsP A “bag of words” is a representation of the words in a phrase or passage, irrespective of order.For example, bag of words represents the following three phrases identically:
Each word is mapped to an index in a sparse vector, where the vector has an index for every word in the vocabulary. For example, the phrase the dog jumps is mapped into a feature vector with non-zero values at the three indices corresponding to the words the, dog, and jumps. The non-zero value can be any of the following:
The post What is bag of words in Machine Learning? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/37KxoF4 Picking the right programming language for Blockchain can have a huge impact on a Blockchain platform’s future success.Security is obviously the main concern — not least because a vulnerability can have a fatal effect on confidence in a network. When selecting a programming language, this should be top of the list. Given the fact that anyone can add to a blockchain and access the code, it’s also worth producing code — and building a network — that can withstand as many requests as users are willing to throw at it. If it’s unable to perform to the standard required, and buckles under the pressure because it’s not versatile enough, this could be disastrous for scalability and development in the future. The post Why is picking the right programming language for Blockchain so important? appeared first on Data Science PR. Originally from Machine Learning & AI – Data Science PR https://ift.tt/3p1HSG0 |

 RSS Feed
RSS Feed
